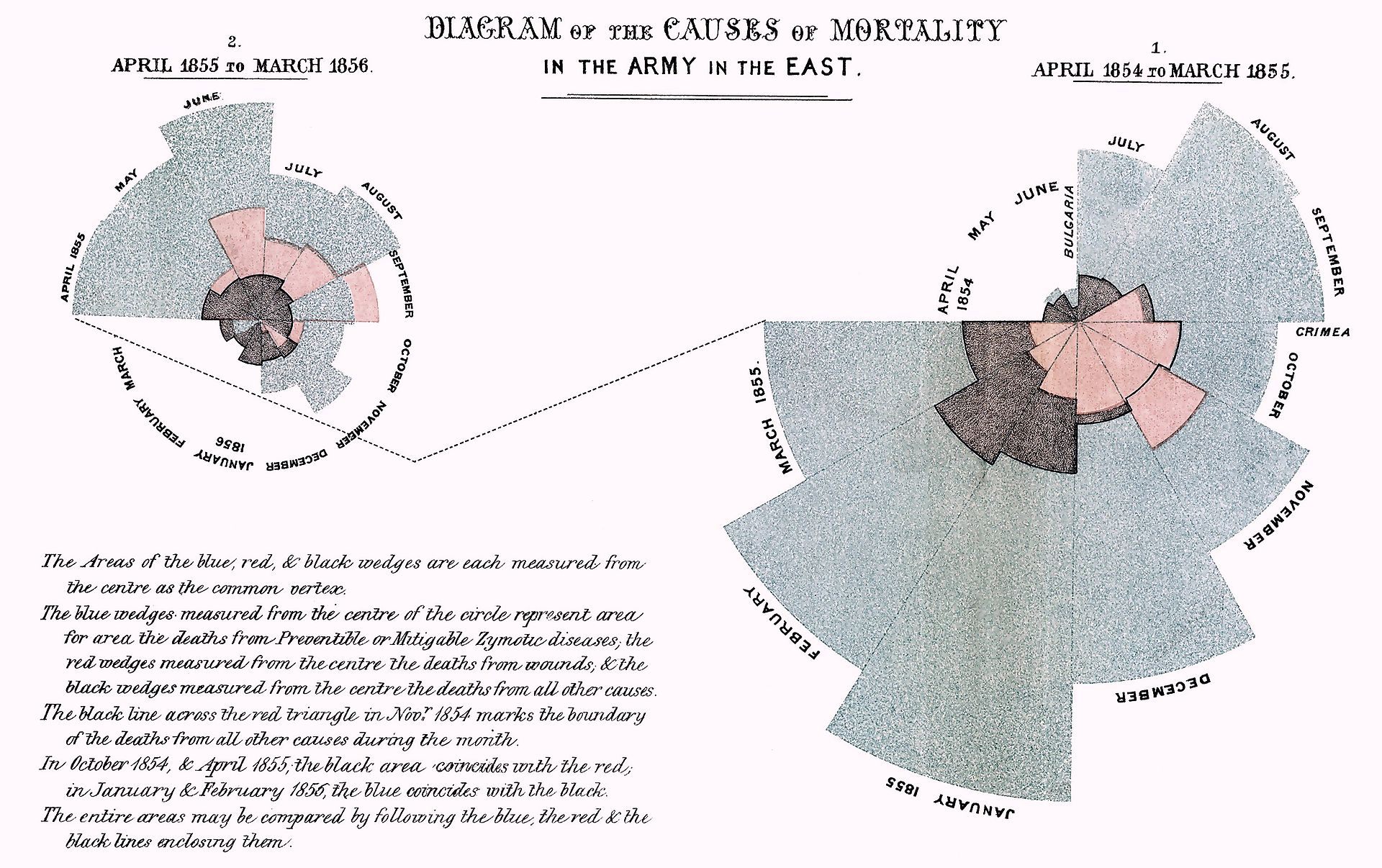
I wore my watch for the first few days of not running, still using it to record the morning walks with the dog. But as the messages about my activity level started to exacerbate my anxiety – I was already feeling shitty enough, thank you very much – I took the watch off. “The body keeps the score,” [to borrow a phrase](https://bookshop.org/a/93920/9780143127741?ref=2ndbreakfast.audreywatters.com), and there’s no need for me to hand my activity data over to a gadget that’s going to develop its own score, one that may or may not coincide with how I feel, physically and/or mentally.
Source: Un-watching, Un-tracking: Healing and Bad Data by Audrey Watters
—
Audrey Watters reflects on the limitations to smart devices and tracking apps. Whether it is reminders that lack context or the algorithms behind the feedback, Watters wonders if sometimes we can achieve the same outcome by keeping a paper journal or knowing the distances you are running.
This reminds me of danah boyd’s reflection on the addictive nature of statistics.
Stats have this terrible way of turning you — or, at least, me — into a zombie. I know that they don’t say anything. I know that huge chunks of my Twitter followers are bots, that I could’ve bought my way to a higher Amazon ranking, that my Medium stats say nothing about the quality of my work, and that I should not treat any number out there as a mechanism for self-evaluation of my worth as a human being. And yet, when there are numbers beckoning, I am no better than a moth who sees a fire.
Source: My name is danah and I’m a stats addict by danah boyd